Recent Advances of Modeling in Applied and Natural Sciences
The short communication brings about recent advances of modeling in applied and natural sciences. Evidences from abstracted knowledge is used for the modeling of problems. Abstracted knowledge in applied and natural sciences corresponding to different problems may range from rich (complete) evidence base to poor (incomplete) evidence base. The different problems related to the use of evidence base are from diagnosis and treatment of various diseases to risk from large-scale disasters. Current developments as an alternative to trial and error method/approach for solving problems as one of the fundamental method/approaches will be briefed in the paper.
Introduction
Abstracted knowledge in applied and natural sciences corresponding to different problems may range from rich (complete) evidence base to poor (incomplete) evidence base. In the case of rich (complete) evidence base of abstracted knowledge, the relationships (governing equations) between the dependent and independent parameters are well-defined. Models based on such relationships can be referred as precise (certain) type; for example, (i) Assessment of enzyme immobilization for diagnosis and treatment of various diseases: It is used extensively in process industries that include industrial catalysis, analytical application, medical/therapeutic application and bio–separation; and (ii) Classical mechanics, which are derived from first principles.
Whereas in the case of poor (incomplete) evidence base of abstracted knowledge, the relationships between the identified parameters will be ill defined. Models based on such relationships can be referred to imprecise (uncertain) type; for example, (i) Drug discovery for new candidate medications in the fields of medicine, biotechnology and pharmacology; and (ii) Modeling risk from large-scale disasters based on probabilistic or fuzzy set approach. When the evidence base of abstracted knowledge is neither rich nor poor but is in between rich and poor, the relationships between the identified parameters are generally defined empirically. Based on the source of the evidence base, models have been characterized broadly as shown in Figure 1. Models based on such relationships can be classified as empirical type; for example, (i) Prediction of the molecular structure of molecules using more accurate quantum chemical methods, to find stationary points on the energy surface as the position of the nuclei is varied, (ii) clauses in engineering codes of practice, and (iii) Rankin’s formula for design of columns. Similarly, empirical and possibility solutions are classified under inductive based modeling, and exact (closed form) solutions derived from theories (first principles) are classified under deductive based modeling as depicted in Fig. 1. Inductive and deductive based models are also known as data-driven and non-data-driven models, respectively. These models have been influenced by the arrival of computers during and after 1950s. Trial and error method/approach is considered as one of the fundamental method/approaches for solving problems, which are modeled deductively and also for inductive modeling of problems that primarily depend on data.
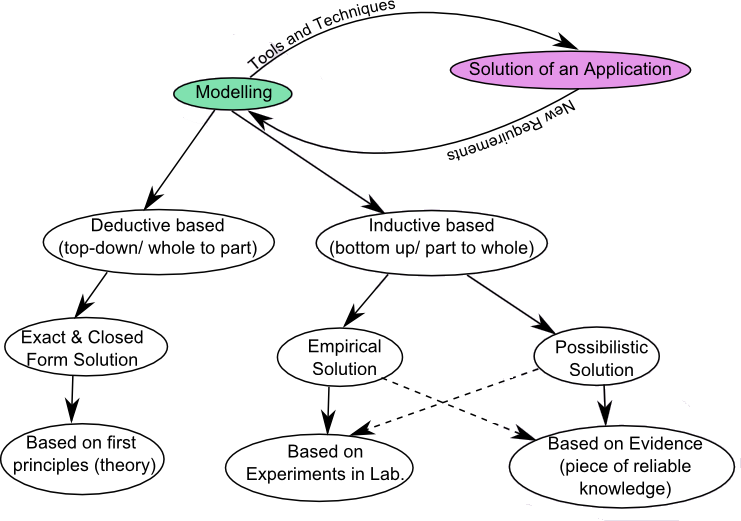
In this paper, current developments in machine learning / data mining techniques as an alternative to trial and error method for inductive (data-driven) and deductive models have been briefly brought out.
Inductively Modeled Problems
Several research-works providing alternative to trial and error method appeared recently for inductive models using simulation-driven and data-driven approaches under the Materials Genome Initiative [1]. This initiative has shown promising results and led to Material Genome Project at MIT, USA [2]. Similarly, another initiative on finding the ground state of the crystal and electron arrangement in which the energy was minimum has shown promising results in spite of earlier standard methods had to undergo too much of trial and error [3]. Moreover, in another research work about how machine learning seeks to develop methods for computers to improve their performance for certain tasks based on observed data [4]. Most of these works highlight the use of simulation- and data-driven approaches, which is a process of extracting patterns from data.
In Inductive Modeling, patterns in data and their relationship can be identified using machine-learning techniques. Machine learning is a field of study that gives computers the capacity to learn without being explicitly programmed [5]. It involves in construction of algorithms that can learn from data [6] rather than following static program instructions [7]. For example, a Bayesian network could represent the probabilistic relationships [4] between diseases and symptoms. Given symptoms, the developed network can be used to estimate the probabilities of the presence of various diseases [7]. Many machine leaning techniques are available in the literature, namely, decision tree learning, association rule learning, artificial neural networks, deep learning, inductive logic programming, support vector machines, clustering, Bayesian networks, reinforcement learning, representation learning, similarity and metric learning, sparse dictionary learning, and genetic algorithms.
In inductive modeling, the data/information used to build a model is called as problem space. For instance, a problem space has been built based on the research conducted on origin of the human malaria parasite Plasmodium falciparum in gorillas [8] to build a model by machine learning using the training data of malaria parasite sequence. The extraction of all valid solutions from the identified problem space has been known as solution space.
Deductively Modeled Problems
The methods to handle deductive models were developed well before the advancement of data mining and machine learning techniques of computer software. Deductive models can find wider use in science, engineering, biology, business, psychology, sociology, computer science, and industry. Model of a real-life problem can be formulated with a set of interdependent parameters (independent and dependent variable) and governing equations. Trial and error is a fundamental method of solving these problems [9], which fall into a broad category of Constraint Satisfaction Problems (CSPs). CSPs are a subject of intensive research in theoretical computer science, artificial intelligence, and operations research. They provide a common basis for exploration of a large number of problems with both theoretical and practical importance. Similar to the way in which a biochemist proposes a chemical reagent and then performs clinical tests, trial and error approach is adopted to search for a solution of a CSP, where inputs are either un-known or not specific. For instance, when an infectious disease outbreaks, because of an unknown virus, biochemists need to find diagnostic reagents that have no serious side effects. In a simplified formulation, this involves a search for a reagent that satisfies a collection of constraints [10]. It has also been used extensively in product design and experiments [11]. The trial and error approach generally advances by adaptively posing a sequence of a candidate solutions and observing their validity. If a proposed candidate solution is found to be valid, then the assignment is accomplished; and otherwise, an error is signaled to proceed with next iteration [12]. An important feature of this approach is problem-specific: trial and error makes no take on to generalize a solution to other problems, and non-optimal: trial and error is an attempt to find a solution for a given precise values, not all solutions, and not the best solution [13]. The most critical ingredient in the trial and error approach is how to employ previously returned errors to propose future trials.
Concluding Remarks
The classification of evidence bases of abstracted knowledge used for modeling is presented. Different case studies from diagnosis and treatment of various diseases to risk from large-scale disasters related to the use of evidence base has been highlighted. Current developments in modeling for solving problems as an alternative to trial and error method/approach is explained.
References
-
Paul R, Katherine CE, Adler PD, Falk C, Wenny M, et al. (2016) Machine-Learning-Assisted Materials Discovery Using Failed Experiments. Nature 533: 73- 76.
-
Nicola Nosengo (2016) Can Artificial Intelligence Create The Next Wonder Material?. Nature 533(7601): 22-25.
-
Curtarolo S, Morgan D, Persson K, Rodgers J, Ceder G (2003) Predicting Crystal Structures With Data Mining Of Quantum Calculations. Phys Rev Lett 9(13): 135503.
-
Zoubin Ghahramani (2015) Probabilistic Machine Learning And Artificial Intelligence. Nature 521: 452- 459.
-
Phil Simon (2013) Too Big to Ignore: The Business Case for Big Data. Wiley, pp: 89.
-
Kohavi R, Foster P (1998) Glossary Of Terms. Machine Learning 30: 271-274.
-
(2016) Machine Learning,
-
Weimin L, Yingying L, Gerald HL, Rebecca SR, Joel DR, et al. (2010) Origin Of The Human Malaria Parasite Plasmodium Falciparum In Gorillas. Nature 467(7314): 420-425.
-
Radnitzky G, Bartley WW, Popper KR (1987) Evolutionary Epistemology, Rationality, and the Sociology of Knowledge. Open Court Publishing.
-
Xiaohui B, Ning C, Shengyu Z (2013) On the Complexity of Trial and Error. 45th ACM Symposium on the Theory of Computing (STOC, Palo Alto, California, USA.
-
Montgomery D (2008) Design and Analysis of Experiments. 7th (Edn.), Wiley.
-
Furuta, Aya (2012) One Thing Is Certain: Heisenberg's Uncertainty Principle Is Not Dead. Scientific American.
-
(2015) Trial and Error.
- Lessons to Learn: Trees are More than the Lungs of the World
- Community Forestry Enterprises as a Model for Sustainable Forest Development: The Case Of The "Baja Tarahumara" in Chihuahua, Mexico
- Ecological and Socio-Economic Impacts of Chromolaena odorata and Mesosphaerum suaveolens, Two Invasive Alien Species in Central and Southern Benin, West Africa
- Epigenetic Sustainability: Modeling the Human Factor as a Natural Resource through Science 4.0 and the NR3C1 Biological Pilot
- Growth-at-Risk: A Framework for Assessing Economic Vulnerability
- The Rural Territory as a Socioecological System for the Management of Public Policy for Sustainable Rural Development