Authentication System for Exam Halls Using Face Biometrics by Artificial Intelligence
Authentication has consistently been the biggest difficulty during exams. Verifying candidates' test eligibility is a difficult process that takes time after typical candidate screening. The project's goal is to combat this by preventing impersonation by exploiting the candidate's facial biometric traits, which are recognized by the DCNN algorithm. The Exam Hall Authentication System Using Face Biometric is a cutting-edge solution designed to enhance the security and integrity of examination halls by utilizing facial recognition technology. Traditional methods of verifying the identity of individuals in exam halls, such as ID card checks or manual supervision, can be prone to human errors and fraudulent activities. This system aims to overcome these challenges by leveraging the unique characteristics of an individual's face for authentication purposes. The enrolment stage and the verification of identities phase are the system's two primary parts. Each exam participant's face characteristics are photographed and safely saved in a database throughout the enrolment step. High-resolution cameras are used in this procedure to take several pictures of the participant's face from different perspectives. The positioning of facial characteristics and particular contours of the face are then extracted from these photos via processing and analysis. In the authentication phase, when an individual enters the exam hall, their face is captured by the cameras installed at strategic locations. The captured image is compared with the enrolled images stored in the database. Advanced algorithms are employed to perform a comprehensive analysis of the facial features, ensuring accurate identification and authentication of the individual. If a match is found, the system grants access to the exam hall; otherwise, it denies entry and alerts the invigilators about the potential unauthorized presence. The Exam Hall Authentication System offers several advantages over traditional authentication methods. Firstly, it significantly reduces the risk of impersonation and cheating, as the system is capable of detecting attempts to use fake identities or masks. Secondly, it improves the efficiency and speed of the authentication process, eliminating the need for manual verification and reducing waiting times for exam participants. Thirdly, the system provides a reliable and audit able record of attendance, which can be crucial for ensuring the integrity of the examination process. In conclusion, the Exam Hall Authentication System Using Face Biometric is a robust and secure solution that enhances the security and efficiency of examination halls. By leveraging facial recognition technology, it provides reliable authentication, reduces the risk of fraud, and ensures a fair and transparent examination environment
Introduction
Overview
The enrolment stage and the verification of identities phase are the system’s two primary parts. Each exam participant’s face characteristics are photographed and safely saved in a database throughout the enrolment step. High-resolution cameras are used in this procedure to take several pictures of the participant’s facial from different perspectives. The positioning of facial characteristics and particular contours of the face are then extracted from these photos via processing and analysis [1].
Examination System: Exams and exams both are great instruments for determining the amount a student has learned about a particular subject. Exams will demonstrate what lessons each student remembered and showed the most interest in. Exams are a fantastic way for teachers to get to know each student personally since every student is so different. Through their work in the test context, instructors may gauge how their students argue and think independently, which is a crucial ability to maintain for following class activities.

Exams are given to students in order to gauge their proficiency in the subject matter they have been enrolled in, as well as their capacity to comprehend and apply new information. Depends on the feedback of the exam, its assessment is able to classify the students according to standard, separating the high-quality students who have mastered the subject matter from the rest.
The Importance of Tests in a Person’s Life: Various categories may be created for exams depending on a variety of variables. Here are a few of these dimensions: Exams with High Stakes: These exams may have a significant influence on a person’s life. The 10th and 12th- grade board exams as well as university-level exams, which may be semester or yearly exams, are examples of such tests in our nation. Exams with a Medium Stake: These tests have a medium influence on our life or a medium stake. Examples of these tests include the Science Olympiad Competition, Scholarship Exams, National Talent Competition, etc. Exams with Low Stakes: These tests are very important, it’s bearing on our daily life or it can help to bright our carry. Examples of these exams include practice exams, class tests, and mock exams etc.
The Frequency of the Examinations’ Administration: Semester Examinations: Based on a semester-by-semester structure, universities conduct final evaluations based on both an external evaluation conducted by universities and an internal evaluation performed by various types of universities through class tests, sessional performances, and practical exams. These are carried out at the conclusion of every semester [2].
Exams are given yearly by a university to evaluate the accomplishments of pupils at the conclusion of the academic year. It is based on a mixture of internal assessments (performed by colleges), practical assessments (performed by colleges), and external assessments (performed by the University itself).
The Purpose of the Exams: Summative Tests: A formative exam, which may be given at the end of a season or once a year, tries to evaluate students’ learning after a lesson. In terms of the examinations, it is practically the halfway point level. Preparation Exams: The preparatory test serves the same function as a pre-university exam. The examination will be given at its greatest difficulty only to pupils who are needed to take it before the final exam, giving them time to make it. Supplementary Exams: These tests, which are administered by universities, provide students who failed the primary exam a second opportunity.
The Kind of Course Material Being Evaluated: Examinations in Theory: This sort of test comprises theoretical examinations for a variety of courses that are administered by colleges, universities, and schools. Practical Exams: Following the theoretical exams, this sort of test component also includes a practical exam. The practical tests must be administered to the applicant whether in the college/school or any other designated location. Exams Given During Sessions: Colleges must provide these tests as part of their on-going evaluation of students’ performance. For instance, using in-class exams, quizzes, etc. Examining Procedures: Pen and Paper Tests: These tests are given physically, and students write their answers on paper while they take the test. This form of administration is used for the majority of subjective and open-ended university exams. Computer-Based: On a laptop, iPad, or other smartphone or tablet, these tests occur. Questions for the test often come from an internet database, and candidates may take the examination at home or at an assessment centre. Exam management systems are cutting-edge web-enabled programs like Smart Exam or U Can Assess that can assist in effectively organizing university exams or online exams. Over a long period of time, they have been employed by universities including Banaras Hindu University, University of Mysore, and Tezpur University [3]. Problem Determined: On a laptop, iPad, or other smartphone or tablet, these tests are performed. Questions for the test often come from an internet database, and candidates may take the examination at home or at an assessment centre.
Formal written exams have grown commonplace in universities, schools, and other educational institutions in the twenty-first century. Over time, more and more examinations were used to choose candidates for all services and professions. The most popular approach has historically been standard testing, although the reliability and legitimacy of the wider variety of modern evaluation procedures have come under scrutiny. Today, the functioning of our increasingly electronically networked information society depends on accurate automated personal identification. Conventional automatic personal identification systems that rely on something you know, like an ID card, a personal identification number (PIN), a key, etc., to verify a person’s identity are no longer regarded as being trustworthy enough to meet the security standards of electronic transactions or distinguish between an authorized person and a forger who has illegally obtained the authorized person’s access privileges. Malpractice is the main issue with the examination system. This is apparent since neither offline nor online exams have a reliable identity verification method. Researchers have concentrated on using biometrics and artificial intelligence to solve the aforementioned issue. A person is individually identified by their physiological or behavioural traits using a technique called biometrics. It depends on something about you to establish personal identity and can tell the difference between a legitimate individual and a dishonest impostor. Since face recognition is essential in the interaction between humans and computers and is often used in security systems, commercial monitoring, etc., face recognition has become a hot issue in actual AI applications [4].
Combining artificial intelligence with physical acceleration has improved the efficiency of systems that identify faces. Face recognition becomes more secure and tougher to copy, even if the recognition of fingerprints is less complicated. Depending on the situation, the use of facial recognition provides a number of advantages. For instance, an automated facial recognition technology is used at airport border controls to confirm the identification of the traveller, expediting the inspection procedure and conserving personnel. Additionally, businesses employ facial recognition for access control to speed up authorized workers admission and eliminate manual discretion.
Artificial Intelligence (AI)
Artificial intelligence (AI) is the area of computer science that focuses on finding solutions to cognitive issues like learning, problem-solving, and pattern recognition that are often linked to human intelligence. Artificial intelligence (commonly shortened as “AI”) may evoke robots or future imagery, but it extends well beyond the automatons of science fiction to include the non-fiction of contemporary sophisticated computer science. The “five tribes” of machine learning, according to Professor Pedro Domingo’s, a well- known researcher in this area, are the symbolists (with roots in logic and philosophy), connectionists (with roots in neuroscience), revolutionaries (with roots in evolutionary biology), Bayesians (with roots in statistics and probability), and analogizes (with roots in psychology). Bayesians have recently been effective in advancing the science in a variety of areas under the moniker “machine learning” due to improvements in the speed of statistical calculation. Similar to how network processing breakthroughs have prompted connectionists to pursue “deep learning” as a discipline. Computer science topics such as machine learning (ML) and deep learning (DL) are both developed from the study of artificial intelligence [5].
In general, these methods are divided into “supervised” and “unsupervised” learning methods, where “supervised” makes use of training data that contains the intended output and “unsupervised” does so.
With more data, AI gets “smarter” and learns faster, and businesses are constantly producing this fuel for running machine learning and deep learning solutions, whether it be gathered and extracted from a data warehouse like Amazon Redshift, verified by “the crowd” using Mechanical Turk, or dynamically mined using Kinesis Streams. Additionally, as IOT has developed, sensor technology has drastically increased the quantity of data that can be studied from sources, locations, things, and events that were previously mostly untapped.
AI History: Artificial intelligence has a long history that dates back to ancient Greece. But it was the development of electronic computers that made AI a reality. It should be noted that as technology advances, what constitutes AI has evolved. For instance, a few decades ago, basic arithmetic or optimum character recognition (OCR) computers that could be programmed were considered to be AI. OCR and simple math operations are no longer regarded as AI but rather as Fundamental Computer System Operations:
- The 1950s - Computing Machinery and Intelligence are published in The Mind by Alan Turing, who gained notoriety for cracking the Nazis’ WWII ENIGMA code. He makes an effort to address the issue of whether or not computers can think. The Turing Test, which examines if a machine exhibits the same level of intellect as a person, is described by him. According to the test, an AI system should be able to converse with a human being without the human being realizing they are speaking to an AI system. At Dartmouth College, the first-ever AI conference is convened. The phrase “artificial intelligence” was originally used in this context.
- 1960s - Through DARPA, the US Department of Defence shows a strong interest in AI and starts to create computer algorithms that resemble human thinking. The Mark 1 Perceptron computer is created by Frank Rosenblatt using a neural network that gains knowledge via experience.
- DARPA completes a number of street mapping projects in the 1970s.
- 1980s - A new, more advanced wave of AI appears. AI systems often use neural networks using back propagation methods.
- Exponentially increasing amounts of data were created in the 1990s. Numerous data sets are processed swiftly by powerful computers. Garry Kasparov is twice defeated by the Deep Blue supercomputer. The genome sequencing effort and other such endeavours produce a ton of information. The development of computing has made it feasible to store, access, and analyse this data.
- The Internet Revolution in the 2000s propels AI to previously unheard-of levels. Big data has become a business buzzword. Before Alexia, Siri, Crotona, and Google Assistant became well-known names, DARPA releases intelligent personal assistants. This opens the door for the automation and reasoning seen in modern personal computers and smartphones. This includes sophisticated search and decision-making tools that assist and enhance human talents.
- Baidu, the dominant search engine in China, uses a kind of convolutional neural network to recognize, examine, and categorize images more correctly than the typical individual in the year 2010. The present Go world champion Lee Sodol is defeated by Deep Mind’s Alpha Go deep neural network computer in a five-game match. Go is a challenging game from ancient China, far harder than chess.
AI In Daily Life: Here are a few AI-powered apps you may not be aware of:
- Online marketing and shopping
- Users often get personalized recommendations from artificial intelligence according to their previous internet searches, buying decisions, or other behaviour. AI is essential to business since it helps with product optimization, inventory management, and shipping, among other things.
- Online searches. Search engines use the copious amounts of data that users supply as input to figure out how to provide relevant search results [6].
Automated Translations
Text-based or spoken-word software for translating makes use of artificial intelligence to produce and improve translations. Regarding capabilities like programmed subtitling, the same is true. Smart cities, homes and technology. In order to conserve energy, electronic thermostats learn from our behaviours, while intelligent urban planners try to manage traffic in order to improve connection and reduce bottlenecks.
Motorcars
Despite they are still uncommon, self-driving vehicles still involve AI-driven safety systems. For instance, the EU has helped to finance VI-DAS, computerized sensors that may identify potentially dangerous situations and incidents. Guidance is often powered by AI.
Cyber security
Artificial intelligence (AI) devices may help in recognizing and thwarting cyber-attacks and other online hazards based on the continuous input of data, detection of patterns, and action replay.
Intuitive Technology against Covid-19
The Covid-19 example shows how AI has been utilized for imaging purposes at airlines as well as other places. Computerized tomography pulmonary scans may be employed in health to find infections. Additionally, data has been utilized to monitor the disease’s spread.
Combating False Information
Certain AI algorithms may identify disinformation and false information by examining publicly available data, looking for dramatic or alarming phrases, and figuring out which internet sources are regarded as trustworthy.
Deep Learning
A topic of machine learning known as deep learning stacks algorithms on the top of one another to better understand the data. As opposed to a simpler regression, the algorithms are no longer limited to providing a collection of relationships that can be explained. Deep learning, on the other hand, uses use non-linear algorithmic layers to construct spread models that communicate depending on a range of variables. Deep learning systems may start to recognize links between items given massive data collections. Words, colours, shapes, and other elements may all have links with one another. On the basis of this, the technology may subsequently be used to make predictions. The capacity of the system to find interconnections or links that human beings would not even be capable to perceive or that could not be effectively encoded in software by people is the source of deep learning’s strength in machine learning and artificial intelligence. As a result, with sufficient training, the network of algorithms may begin predicting or interpreting exceedingly complex data [7].
Image and Video Segmentation and Classification
On a range of vision-related tasks, such as object categorization, convolutional neural networks performed better than people. The combination of systems may start figuring out the image’s topic given millions of assigned photographs. Deep learning-based photo storage systems often include facial recognition capabilities.
Project Scope
Here, we suggest a facial recognition-based authentication solution for exam rooms. Individuals who have not had their fingerprints confirmed by the software will be barred, only those with verified identities may continue.
The Project’s Objective
The primary goal of this initiative is to identify a legitimate individual (student) from an imposter before they enter the test hall. The project’s mission is to employ facial identification to confirm an individual’s identity. In order to help prevent test impersonation, this project will create Face Biometric Based test Hall Authentication systems.
Literature Review
Hybrid Face Detection Algorithm to Prevent Racial Inequity Due to Dark Skin
The last two decades have seen a major advancement in face recognition technology. Various organizations and governments have made extensive use of this technology for military, security, and surveillance initiatives. Additionally, it is increasingly a part of our everyday lives via consumer apps, personal information safety, and cyber-security, especially when utilizing cell phones. The majority of this technology operates fairly well, although there are some issues with the accuracy of the findings when evaluated on pictures of persons with a dark complexion. The inaccuracy of the current face recognition algorithms when used on persons with dark complexion is highlighted in this article. The key innovation is a hybrid approach that improves face detection for those with dark complexion by combining a Gaussian distribution and explicit rule framework. The findings showed that the face identification rate for those with a dark complexion was best enhanced by the hybrid Gaussian and Explicit Rule method [8].
Advantages
- It is quite accurate.
- Both efficiency and time requirements are minimal. Disadvantages
- It is difficult to accurately identify persons with dark complexion.
- The detection of skin tone variance among racial groups has been regarded as a key issue for all skin modelling systems.
An End-To-End Framework for Emotion Recognition Based on the Temporal Aggregation of Multi Modal Data
Humans use a variety of modalities to express and experience their emotions. The human sensory mechanism fuses multi modal data in a complicated way that is inherent to it. Rapid processing is accomplished by employing basic convolution neural networks (CNNs) to extract the characteristic properties of both visual and audio displays. Undoubtedly, both in terms of the labour and knowledge necessary, gathering annotated training data continues to be a significant barrier to training emotion detection algorithms. The recommended from beginning to end neural network design, known as TA-AVN, solves this problem by providing a natural reinforcement mechanism that permits reaching high levels of precision even when the amount of annotations for training is constrained. The method suggested in this article can be easily modified to function even when there is a limited amount of annotated data available.
It employs an arbitrary choice of analysis windows gathered from individual temporal segments of the input video and depends on a revolutionary audio-visual fusing multisensory architecture for emotional identification [9].
Advantages
- It is effective to use and adaptable in merging audio and visual data from many modalities at various sample rates.
- The suggested solution has low computational complexity.
Disadvantages:
- Obtaining annotated training data continues to be a significant obstacle in the development of emotion detection systems.
- Its efficiency and accuracy are both poor.
- A laborious task.
Identifying False Images Using Deep Learning Neural Networks and Tracing Information Extractors
A rise in realistic-looking untrue facial media created by Artificial Intelligence, there are Deep False or Face to Face, that manipulates individual faces and emotions has occurred since the development of computer vision and deep learning. Although the false faces were mostly made for amusement, misuse has sparked societal dissatisfaction. For instance, false pornography created by Deep False has led to the exposure of several celebrities. Concerns regarding Face to Face’s bogus political speech videos are also growing. It is essential to create models that can identify phony faces in media to protect people’s privacy in addition to social, political, and global security. To improve the effectiveness of manipulation detection, this research suggests a hybrid face investigations framework that utilizes convolutional neural networks that combines the two forensics methodologies. An open Face to Face datasets and a unique Big False datasets that we have collected one are utilized to verify the proposed system. The proposed approach simultaneously extracts content features and traces data from a face image using two separate feature extraction devices. Convolutional neural networks are used in this way. A previously trained object recognition model’s feature mining technique is carried across and modified to train the previously featured extraction. The qualities that are retrieved are thereby adjusted to represent certain face features. Prior to applying multiple channels of communication limited convolution, which is the last feature extraction algorithm conducts local convergence, which relies on the connections between nearby pixels [10].
Advantages • It efficiently learns the many traits of fake methods of manipulation and achieves the greatest accuracy across all video encoding levels when compared with baseline models, proving its durability.
Disadvantages • It is less efficient and inaccurate.
Attendance System Designed Around Real-Time Processing of Video and Face Recognition
The administration of college students has to be improved since managing students’ college attendance has emerged as one of the most contentious topics in society. Although most college students still use paper signatures or teacher orders for daily attendance, According to certain emerging methodologies, as technologies develop, some schools and universities may eventually use punch card fingerprints and intelligent participation techniques. Although there are many ways to boost participation, the outcomes are often poor. To resolve the aforementioned problems, this article suggests using a linear discriminant evaluation (LDA) technique. By decreasing inter class dispersion within each category while maximizing inter class dispersion, a set of quadratic changes is sought by this method [5].
Advantages
Manual fingerprint punching and recognition of faces time attendance systems are more dependable and reliable at identifying check-ins. The efficiency is dramatically enhanced, which might deter pupils from leaving class early and skipping it. The rate of class leaving is much lower than the control group, just approximately 13%.
Disadvantages
Using real-time video analysing, it is challenging to examine the display parameters of the face identification record of attendance. The face identification system for attendance with real-time processing of videos has a very poor accuracy rate and a low level of stability. Learning Heterogeneous Face Recognition Domain-Invariant Discriminative Features Heterogeneous recognition of faces (HFR), or matching face images over several domains, is a challenging problem because of the large cross-domain variance and a dearth of matched cross-domain training information. This research proposes a quadruplet architecture that integrates domain- level and class-level alignments into one, coherent network to train domain-invariant discriminative features (DIDF) for HFR. Domain-level realignment reduces the discrepancy in cross-domain distribution. The hostile equilibrium and misaligned problems that the domain-level alignment faces are addressed by the class-level alignment, which is based on a special quadruplet loss. This is done by further lowering intra-class variability and boosting inter-class separateness across cases. Extensive tests on four challenging benchmarks and quantitative assessments against other state-of-the- art HFR methods demonstrate the value and efficiency of the recommended DIDF technique in heterogeneity face recognition.
Merits
- When it comes to developing domain-invariant discriminating characteristics for HFR, the suggested DIDF system excels.
- DIDF is a general platform that also includes inner components for extra challenges like location, and expression-invariant face recognition may be substituted or enhanced.
Demerits
- Matching face pictures across several domains is a challenging process.
- Low reliability and insufficient pairwise cross-modality training data.
Multi-Task Cascaded Face Recognition Employing A Receptiveness Field
Neural networks with convolutions: Face detection techniques have advanced the most with deep learning’s on-going development. The most popular structure for real- time detection continues to be cascade CNN based on the featherweight model, which predicts faces in a coarse-to-fine way with good generalization capabilities. It is not necessary for an input with a defined size, unlike other approaches. MTCNN still performs poorly in detecting small objects, however. In order to improve the feature discriminability and resilience for tiny targets, this research suggests a novel face detection model called RFEMTCNN that makes use of the Inception-V2 block and responsive field block. In order to enforce correspondences between feature maps and categories, prevent over fitting, and decrease the network parameters, this author employs the Global Average Pooling (GAP) to replace the second-to-last completely connected layers. The AM-Softmax function for loss is added to improve the R-Net’s capacity to discriminate [3].
Merits
- Face detection is really accurate.
- It enhances a model’s capacity for generalization.
- Time requirements are minimal.
Limitations
For detection in real-time, cascading CNN the construction that depends on the lightweight model is still popular.
- It is not necessary if the input has a fixed size.
- Face detection is not done quickly enough.
You Just Moving Once: A Successful Convolutional Neural Network for Face Recognition
In relation to emotion analysis, recognition, personalized services, and other human-cantered “smart city” features, face recognition is often a vital element. Even after years of study, developing high-accuracy real-time face detectors that operate in the open environment remains a challenge. This article recommends using the You Only Move Once (YOMO) real-time facial detection, which comprises various combinations of feature structures in the form of top-bottom and depth-wise separable convolutions. Only faces in the correct scale should be detected by each detection module. Utilizing the random cropped approach, each identification component may be educated by an extensive amount of specimens, which is more suitable for detecting architectures. Under continuous measures of FDDB, the suggested elliptical repressor may significantly increase the detection recall rate. YOMO performs better than other algorithms with 51 FPS for a 544 544 input picture with just 21 million parameters.
Benefits
- Reduced computation.
- Good accuracy and latency support for the security issue of face spoofing detection and exploitation identification.
- Additionally, this approach makes use of elliptical and rectangular bounding boxes, which in practice may better accommodate complicated situations.
Demerits
- Small faces can’t be dealt with.
- The multi-scale inference is low and aids in the detection of varied faces.
- Real-time detection is disabled as a result of high processing costs brought on by complicated network topologies.
Technique For Detecting Faces Using Cascaded Convolutional Network
Face detection benefits significantly from deep learning. Nevertheless, the available approaches need fixed-size input pictures for image processing, and the majority of methods only employ one network for extracting features, which weakens the diagram’s capacity to generalize. Our approach uses a transmitted design with 3rd levels of deep convolutional networks to address the aforementioned issues and enhance detection performance. According to the predictive principle, the convolutional neural network is a face recognition system, according to this article [8].
The neural network eliminates the responsibility of locating facial component locations and replaces the standard convolution in MTCNN with the separated residue component. Therefore, in the detection stage, just the tasks of bounding box regression and face classification are performed. The cascading convolutional neural network and technique of extending the distribution’s width in the separate residue module are used to increase the detecting accuracy of the network. To keep the network computation to a minimum while maintaining a quick detection rate, depth differentiated convolution is utilized.
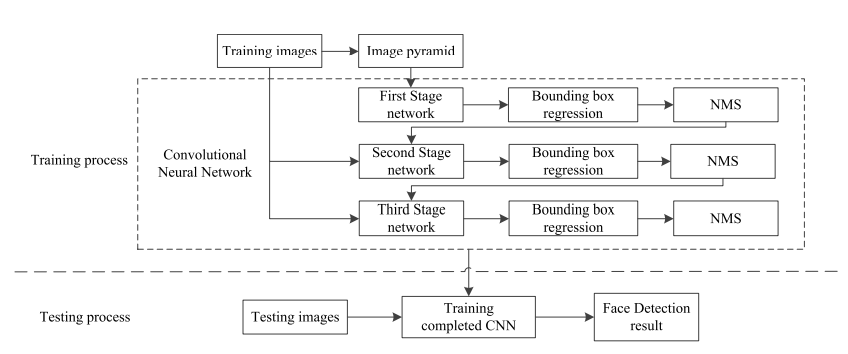
Benefits
- It shortens the training period and enhances the effectiveness of network identification.
- The network creates face candidate windows using a cascade structure, and constructing a multiple-layer network may significantly increase the precision of applicant display location.
- It increases face identification accuracy and guarantees strong real-time performance.
Demerits
- Previous approaches for image processing required fixed-size pictures as input.
- The majority of techniques only use one network for feature extraction, which weakens the generalizability of the framework.
SLR, or Semi-Coupled location Limited Approximation for High-Resolution and Very Low-Resolution Face Awareness, is a term used in the field of face recognition
Although face recognition software has recently had a lot of achievement, challenges involving super-resolution (SR) and identification in real-world uses for very low-resolution (VLR) photographs are more challenging than those using high-resolution (HR) pictures. Because of the unusual discriminatory data found in VLR pictures, the one-to-many map link between HR and VLR images reduces the SR and identification performance. In this study, a semi-coupled vocabulary learning approach was developed for the encoding and translation of VLR pictures of face characteristics. The role of regionally restricted representations in identification and SR tasks, involving choosing parameters and semi- coupled versions optimizing, has been fully studied. The acquired LR characteristics are transformed into HR spaces for concurrent hallucinations and identification.
Merits
- It demonstrates that the suggested strategy outperforms a number of cutting-edge SR and recognition techniques.
- Accuracy is quite good.
- Time requirements are minimal.
Demerits
- The resolution of facial photographs is often quite poor, and the large distance between cameras and targets makes it difficult for current face recognition algorithms to process these thumb-sized VLR facial images.
- Even more challenging than high-resolution (HR) photographs are stance, lighting, and expression variations.
Improving facial identification Algorithms using a fresh Image Enhancing Technique, Hybrid Features, and CNN
Everyone is aware that most facial recognition systems (FRSs) operate less than optimally in unrestricted settings. The absence of really effective photo preliminary processing methods, which are frequently needed before feature extraction and classification processes, might be one factor contributing to this low performance. In addition, it should be emphasized that few face recognition concerns are normally taken into account by most FRSs, which restricts how widely they may be used in real-world circumstances. So, This is anticipated involves putting in place more effective pre-processing techniques would greatly enhance the performance of FRSs, in addition to choosing the appropriate characteristics for classification. Using cutting- edge convolutional neural networks, this study presents a unique enhancement method that has been utilized to increase the recognition of facial features system efficiency in uncontrolled settings. The performance of recognition has been boosted by the presentation of a collection of useful hybrid characteristics that may be retrieved from the augmented pictures. The effectiveness of enhancing facial images to boost recognition accuracy while taking into account all restrictions in the face database has been confirmed by detailed performance analysis.
Benefits
- Utilizing an efficient enhancement technique as a pre- processing method improves functionality in comparison to utilizing face photos that have not been improved.
- When our enhancement approach is utilized in combination with two cutting-edge CNN classification algorithms, the recognition rate increases significantly when compared to other enhancement methods.
- It has been shown that the choice of our hybrid features from the improved face photos affects the improvement in recognition performance.
Demerits:
- Most facial recognition systems (FRSs) perform poorly in unrestricted contexts.
- Lack of very efficient picture pre-processing methods.
- Only minor face recognition flaws are normally taken into account in most FRSs, which restricts how widely they may be used in real-life circumstances.
Method and Analysis
A person may be identified by their face using technology that recognizes faces. It locates, documents, stores, and analyses facial features using machine learning methods in order to match them to images of certain persons in an existing database. Initial strategies mainly focused on constructing effective classifications for identification using traditional machine learning techniques and gathering different types of manually constructed features utilizing computer vision domain knowledge. Such methods have drawbacks since the detection process as a whole can frequently not be tuned, needing the help of computer vision experts to supply valuable characteristics. There are several FR techniques that are now in use and function well.
SVM, Or Support Vector Machine
A common training method called Support Vector Machines (SVM) may be used to create a model that uses several classes of information and discriminate between them. The target of an SVM for the fundamental 2nd class classification issue is to distinguish the two classes using a function inferred from the given samples. A class represents a distinct face in the context of facial recognition, and the SVM seeks to determine what best distinguishes the various feature vectors of one distinct face from the ones of another distinct face.
PCA, Or Principal Component Analysis
The Principal Factor Investigation is a method of statistics that is often used and quoted. By removing the primary component from multi-dimensional data, a mathematical approach produces a dimensionality reduction. By using principal component analysis, the matrix’s Eigen value and Eigen vector problems may be simplified. Simply Principal component analysis is utilized in a broad range of programs, including recognition of patterns, vision in computers, and the processing of digital images. Principal element analysis’ core principle is to reduce a database’s complexity. When communicating a large number of linked attributes, it is important to keep as much of the database’s variance as feasible.
Linear Discriminant Analysis (LDA)
Finding a linear arrangement of characteristics while maintaining class reparability is a common task for LDA. The LDA seeks to give a representation of the distinction between levels, unlike PCA. The LDA obtains different projecting matrices for each level. Fisher differential evaluation is connected to the linear discriminant analysis approach. The local characteristics of the pictures are explained via the method of linear discriminant analysis. Three features-shape feature, colour feature, and texture information-are used to determine the form of pixels in pictures. For locating the angles that separate linearly between pattern features in the pictures, linear discriminant analysis is used. When reducing the inter-class variation in recognizing faces, this approach maximizes inter-class scatter.
NN: Neural Network
Neural networks provide crucial elements for identifying patterns and classification. Kohonen was the first to demonstrate that a neural network can recognize matched and standardized faces. There are methods for identifying characteristics using neural networks. By integrating several methods using instruments like PCA or LCA, a hybrid classification for recognizing faces may be produced. These approaches are bias-added feedback neural networks, PCA-self-organizing maps, multi-layer convolutional neural networks, etc. These could enhance the models’ efficacy.
Using K’s Closest Neighbours
The k-NN method is one of the fundamental classification algorithms used in machine learning. The k-NN method is regarded as a carefully watched Style of learning for machine learning. This is often used in the organization of similar components in search applications. The similarity between the objects is calculated by building a vector illustration of them and then comparing them utilizing the relevant distance metrics. Registration systems, safety devices, and smart home technology are examples of face recognition technologies. A suggested face recognition-based voting method.
Negative Aspects
- The precision of the mechanism is not perfect.
- The activities for importing the initial information and recognizing faces are a tad slow.
- It is able to recognize individuals that are near up.
- The manager of the training set and the teacher both still have some physical labour to undertake.
- Handmade element.
- High Algorithmic Complicatency.
Proposed System
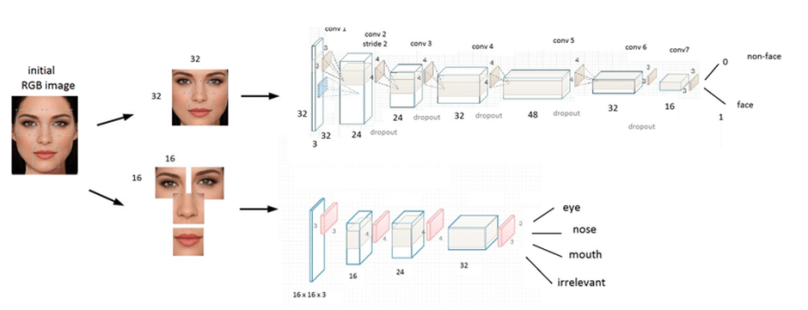
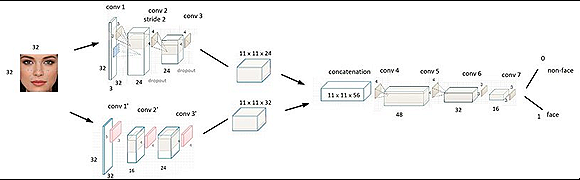
Face recognition and detection technology are used in the testing process to verify identities and track attendance. Hall ticket fraud is the construction of a computerized system that uses the processing of images to impersonate or cross-check hall tickets. Malpractices are the main issue with examination systems. The primary issue is the lack of an effective identity verification method for both offline and online examination systems. An examination system built on face recognition and verification technology, including the security strength of examination and accuracy, is the answer to this issue. Imitation is nothing more than pretending to be someone else for dishonest motives or adopting their characteristics or looks, which is one of the primary issues that must be dealt with in our project. Second, it is determined whether or not the applicant has been verified in cases of impersonation. If the individual is verified, his presence is also noted. Whether the applicant is verified or not, the notification has to be transmitted to the test coordinator via an alert. Convolutional neural networks (CNNs) based on deep learning are used to recognize faces [4].
DCNN for Face Recognition
CNNs are a particular type of artificial network this is particularly good at classifying and identifying images, among other things. A type of complex feedback neural system is a CNN. The filters, the kernels, or synapses with prejudices, variables, and weights that can be trained make up CNNs. Each filter takes inputs and performs convolution, which is and then may or may not perform nonlinearity in depicts a standard CNN diagram. The framework of CNN includes convolutional, collecting, Rectified Linear Unit (ReLU), and Completely Coupled levels.
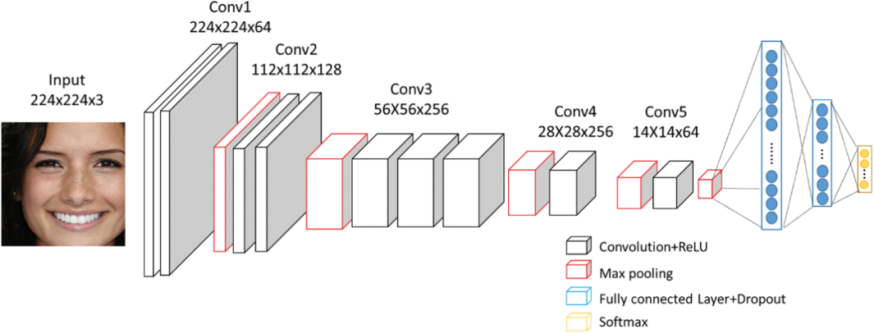
Convolutional Layer
The Convolutional Layer, the essential component of a convolutional network, is the bulk of the computation. The basic objective of the convolution layer is to derive properties from the source of information, which is an image. Convolution acquires image properties by using small squares from the input image to maintain the spatial link between pixels. The incoming image is warped by a set of programmable neurons. The outcome is that the output image has a feature map or activating map, which is subsequently utilized as input information for the next convolutional level.
Pooling Layer
Even if every activated map’s dimension is decreased by the layer that pools data, the most crucial information is still there as well. From the provided pictures, several not overlapping, squares have been produced. Down sampling each region uses a non-linear process, such as average or maximal. Higher generalizing, quicker convergence, and resilience to translating and distortion are all features of this level, which is often placed between layers of convolution.
Re Lu Layer
Assuming that a neuron’s input is supplied as x and that the rectifier is specified in scientific research for neural network simulations as f(x) = max (0, x), we are able to comprehend how the ReLU works. ReLU is a non-linear procedure that uses rectifier-using components, which implies that each of the pixels gets only one use and that each value that is negative in the map of features is substituted with zero.
Fully Connected Layer
Each filter in the layer below it has been linked to every filter in the layer above it, indicating that the layer is fully connected. The result obtained from the convolutional, collecting, and ReLU layers represent the high-level features of the input image. The purpose of employing the FCL is to use these features to split the input image into several groups based on the training data. The layer that feeds the features to the classifier via the process known as Soft max activation is referred to as the last pool layer, or FCL. The Output Probability of the Fully Linked Layer Sum to 1 [2]. Advantages
- The gadget captures the faces it finds and instantly marks whether an individual has gotten dosage 1 or not.
- It utilizes actual-time video data to recognize and alter individuals.
- Don’t allow unauthorized access.
- Face detection on many faces.
- Give techniques to extract as many faces from a picture as possible.
- Multifunctional software.
- Can be utilized in many settings.
- False Alarm.
System Design
Architecture of System
Student Face Enrolment
$$ \mathrm {E} = \mathrm {E} _ {\mathrm {i}} + \mathrm {E} _ {\mathrm {j}} + \mathrm {E} _ {\mathrm {k}} $$ $$ \mathrm {人} = \mathrm {人} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} + \mathrm {C} ^ {2} + \mathrm {D} ^ {2} $$ $$ - 1 $$ Face Frame acquisition $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$ Face Authentication Preprocessing $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {\mathrm {i}} + \mathrm {E} _ {\mathrm {j}} + \mathrm {E} _ {\mathrm {k}} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Face Detection $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Face Recognition $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {法} = \mathrm {法} $$ Feature Extraction $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Face Detection $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$ Classification $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$ Frame Extraction $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {C O} _ {2} + \mathrm {H} _ {2} \mathrm {O} = \mathrm {H C O} _ {3} ^ {-} + \mathrm {O H} ^ {-} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} + \frac {1}{2} \mathrm {D} ^ {2} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Face Recognition $$ - 1 $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$
| Classifie | d Result |
|---|
$$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$
| Feature | Extraction |
|---|
$$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {d} = \mathrm {d} _ {1} + \mathrm {d} _ {2} + \mathrm {d} _ {3} $$ Student $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$ Prediction $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Database Server $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ - 1 $$ Alert $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Admin $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Allow Not - Allow
Flow Chart
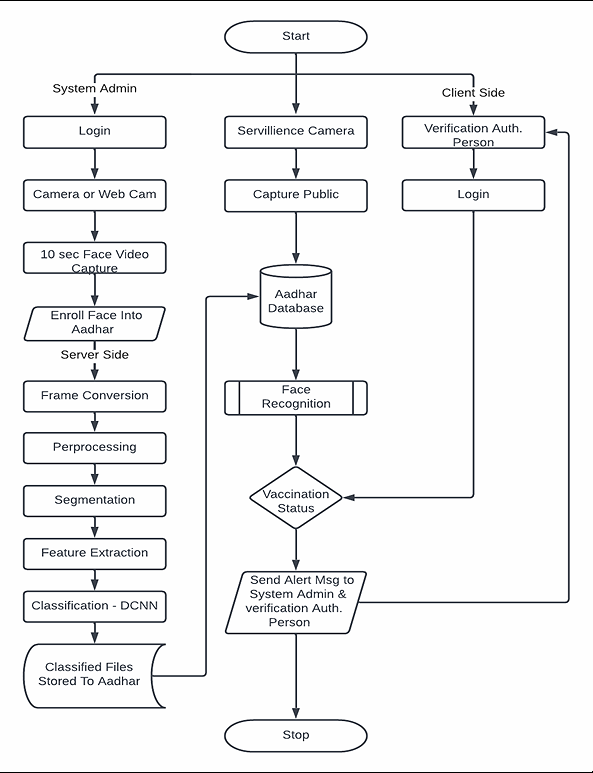
Result and Discussion
Problem Description
The COVID-19 vaccinations are vital, life-saving supplies in the on-going epidemic; hence it is crucial to provide universal, fair access to the vaccinations. Bangladesh is using national digital identities to register people; millions of vulnerable individuals run the danger of not receiving COVID-19 immunizations. However, the use of Aadhaar- based FRT for verification purposes prevents residents from receiving essential vaccinations if they do not have their Aadhaar cards or have not connected them Visit the in-person sign up or the Co Win website, according to the statement.
Module Description
Training Phase FOR THE Face Recognition Module Face Enrolment: The first step in this session is to photograph a few pupils’ front features. Following that, utilizing them as a model, the blueprints for both poses-tilting up or down, advancing closer or more thoroughly, and rotating left or right-are reviewed and recorded. Face Image Capture: ATMs should have cameras installed to record pertinent footage. Webcam is utilized here as the link between the computer and the camera. Extraction of Frames: Fragments are obtained from the video input. This video has to be cut up into sequences of pictures for further processing. The implementation of persons determines how quickly a movie must be split into pictures. From this, we may infer that usually, 20-30 pictures are recorded every second & forwarded the following stages. To maximize the diversity of the photographs, the participant is permitted to turn or move their face while the image is being taken.
Pre-Processing
- Face picture pre-processing refers to the operations carried out for preparing images before they are used by model inference and training. The following steps must be implemented:
- View image
- Grayslake to RGB conversion
- Original picture size (350, 470, 3) - (width, height, and the number of RGB channels)
- Scaled down (220, 220 and 3).
- Denise (remove noise)
- To eliminate undesirable noise, we must smooth our picture. To do it, a Gaussian blur is utilized.
- Binarization.
- A monochrome image’s 256 shades of grey are condensed into only two by the process of “picture binarization”: black and white, or an image that is binary. It does this by converting the original picture to a black-and-white version.
Grey
$$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Resize $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} $$ Face Image Dataset $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Preprocessing Denoising $$ \mathrm {E} = \mathrm {E} _ {\mathrm {i}} + \mathrm {E} _ {\mathrm {j}} + \mathrm {E} _ {\mathrm {k}} $$ Binarization $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Face Detection: Therefore, in this section, the Region Proposal Network (RPN) generates RoIs by sliding windows on a featured image over anchoring various dimensions and facet ratios. Depend on an upgraded RPN, a face detection and segmentation algorithm. RoIs are created using RPN, and RoI Align accurately maintains the precise spatial placements. When the RPN is initially predicting item positions, they are in charge of giving a predetermined set of boundaries of various sizes and percentages that will be utilized as a reference.
Background Exclusion
$$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Priority Subtraction $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ RPN-based Face Segmentation $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} $$ Processed picture $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$
| R | PN |
|---|
$$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$
| R | OI |
|---|
$$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$
Use of the Region-Growing (RG) approach for face-segmenting images
This article describes the region’s growth process and current related studies. Region-Growing (RG): RG is a simple method for segmenting images that depends on the region’s seed. It is sometimes referred to as a pixel-based approach since it selects the first seed spots for the segmentation of an image. This segmentation technique examines the area surrounding pixels of the source image “seed points” and decides whether or not the neighbours should be included in the area depending on certain criteria. In a typical region-growing method, just the “intensity” constraint is used to analyse the neighbouring pixels. The pixels nearby that fulfil the criteria are picked to increase the region after the value of intensity has been compared to a criterion. RPN: An RPN, or a total convolution network, can simultaneously forecast item limitations and objectless ratings for every single spot. The RPN has undergone extensive instruction to offer the best area recommendations. An Anchoring Point is a feature (point) on the CNN feature map that it works on. The middle of these anchor points is where the element map’s anchoring location is located in the image.
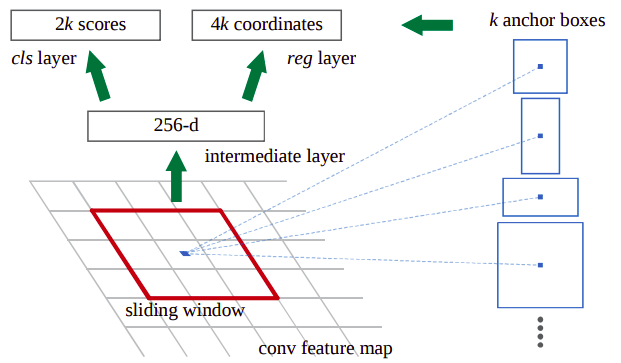
Training of RPN: Be aware that there are nine anchor points for each place on the map of features, making a very large total number that does not include all of the essential anchor boxes. If a thing or a part of an object is contained in an anchor box, we may use it as the primary focus, and if it doesn’t, we may refer to it as the background.
Give an identification to each anchor box for use in training based on how well it intersects (IOU) with the specified reality. We simply assign one of the three different labels-1, -1, or 0-to each anchoring box. Label 1: (Towards front) given the next conditions, an anchor could be assigned labelled 1 if it has the highest IOU in the real world.
If (IOU > 0.7) then the truth IOU is greater than 0. If IOU is less than 0.3, an anchor is given the label “-1” (Background).
Label = 0: If it doesn’t fit into one of the aforementioned categories, this kind of anchor doesn’t help with training and is disregarded.
After labelling the boxes, it generates a mini-batch of 256 anchor boxes that are selected at random taken from the exact same image. The mini-batch ought to include a one-to-one ratio of favourable and negative anchoring boxes; however, when there are fewer than 128 affirmative anchor boxes, we add negative anchor boxes to make up the difference. Now, using back propagation and stochastic gradient descent (SGD), the RPN may be trained from beginning to finish.
The Stages in the Pre Processing are:
- Choose the first seed point.
- Add the surrounding pixels and the Attenuation limit
- Realize the limit of the adjacent point.
- Limits are satisfied-chosen for area-wide expansion.
- “Process is iterated until all regions are finished.” Feature Extraction: Following face identification, the feature extraction module uses the face picture as input to identify the most important aspects for classifications. The lips, nose, and other facial characteristics are automatically collected for each posture, and their relationship to frontal face templates is utilized to determine the variation’s consequences.
Face Qualities
- Forehead Height: Forehead Height is the distance between the highest point of the eyebrows and the top of the forehead.
- Centre Face Height: The height of the centre of the face is measured from the highest point of the nose to the highest point of the brows.
- Low Face Height: the space between the tip of the nose and the base of the jawline.
- Jaw Form: There are several ways to distinguish between various jaw forms. If you utilize face shape acknowledgment, you may change this number; for details, explore (this) book.
- Left Eye point
- Right Eye point
- Eye to Eye Distance: The separation between the nearest margins of the eyes
- Eye to Eyebrow Distance: Depending on which part of the human face is more prone to glance at a monitor, the space between the brow and the eye (left or right) will vary.
- Eyebrows Distance: the space between the brows on the horizontal
- Eyebrow Shape Detector 1: To distinguish between (straight | non-straight) eyebrow forms, measure the angle between three places on the eyebrows (left edge, middle and right edge).
- Eyebrow Shape Detector 2: To distinguish (Curved | Angled) between each brow forms, a number.
- Brow slope
- Detection of eye slope 1: A technique for estimating the eye’s slope. It is the angle between the centre and edge points of the eye. Three different kinds of eye slopes- upward, downward, and straight-are represented by this detector.
- Detection of eye slope 2: Another approach is to determine the eye’s slope. It is the difference between the eye’s centre and edge points on the Y axis. This detector is not a mathematical slope; rather, it is a number that may be divided into three different eye slopes (Upward, Downward, and Straight).
Nose Length Nose breadth: Breadth of the nose’s bottom portion Nose Arch: The position at which the nose’s bottom tip curves (longer nose = more curve = smaller angle). High Lip Height Reduced Lip Height
Model of Grey Level the Co-Occurrence
The term “GLCM” refers to the second-order statistics texture evaluation method. It calculates the regularity with which a group of dots occur within an image at an appropriate distance and orientation and evaluates the spatial connections between pixels. With d = 1, four GLCMs (M) are created for each angle of 0, 45, 90, and 130 degrees after each image is split into 16 shades of grey (0–15). Every GLCM yields five features (Eqs. 13.30–13.34). Therefore, each picture has 20 attributes. Before being sent to the classifiers, the range of each characteristic has been normalized to be between 0 and 1 and each classifier is given an identical set of features. Three categories may be made out of the characteristics we retrieved. The first group of first-order stats includes the highest magnitude, minimum magnitude, median, average, the tenth percentile, the ninety- percentile, standard deviation, variation of energy value, power, chaos, and more. These characteristics describe the tumour region’s Grey level strength.
| Sl.No | GLCM Feature | Formula |
|---|---|---|
| 1 | Contrast | $\sum_{i,j=0}^{N-1} P_{ij} (i-j)^2$ |
| 2 | Correlation | $\sum_{i,j=0}^{N-1} P_{ij} \left[ \frac{(i-_{i})j(i-_{j})}{\sqrt{o_{i}^{2}o_{j}^{2}}} \right]$ |
| 3 | Dissimilarity | $\sum_{i,j=0}^{N-1} P_{ij} |i-j|$ |
| 4 | Energy | $\sum_{i,j=0}^{N-1} P_{ij}^2$ |
| 5 | Entropy | $\sum_{i,j=0}^{N-1} P_{ij} (-\ln P_{ij})$ |
| 6 | Homogeneity | $\sum_{i,j=0}^{N-1} \frac{P_{i,j}}{1+(1-j)^2}$ |
| 7 | Mean | $\dot{i}_{i}=\sum_{i,j=0}^{N-1} i(P_{i,j}) \dot{i}_{j}=\sum_{i,j=0}^{N-1} j(P_{i,j})$ |
| 8 | Variance | $\dot{o}_{i}^{2}=\sum_{i,j=0}^{N-1} P_{ij} (i-\dot{i}_{i})^{2}, \dot{o}_{j}^{2}=\sum_{i,j=0}^{N-1} P_{ij} (j-\dot{i}_{i})^{2}$ |
| 9 | Standard Deviation | $\sigma_{i}=\sqrt{\sigma_{i}^{2}}, \sigma_{j}=\sqrt{\sigma_{j}^{2}}$ |
Table 5: Formulas to calculate Texture Features from GLCM.
Sphericity, lengthening, highest 3D size, greatest 2D size for oriented axially coronal, and coronal aircraft, main axis width, smallest axis length, and least axis size, in addition to quantity, area of surface, and area of surface to volume ratio, are included in the second category of characteristics called impact characteristics. These traits characterize the form of the tumour region. 22th grey-level co-occurrence matrix (GLCM) features,5th neighbouring grey-tone difference matrix (NGTDM) features, 6th grey-level run length matrix (GLRLM), and fourteen grey-level dependence matrix (GLDM) features make up the 3rd category of features, called texture features. These qualities describe the texture of the tumour location Tables 2 & 3.
| image_id | lefteye_x | lefteye_y | righteye_x | righteye_y | nose_x | nose_y | left- mouth_x | left- mouth_y | right- mouth_x | right- mouth_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 000001.jpg | 69 | 109 | 106 | 113 | 77 | 142 | 73 | 152 | 108 | 154 |
| 1 | 000002.jpg | 69 | 110 | 107 | 112 | 81 | 135 | 70 | 151 | 108 | 153 |
| 2 | 000003.jpg | 76 | 112 | 104 | 106 | 108 | 128 | 74 | 156 | 98 | 158 |
| 3 | 000004.jpg | 72 | 113 | 108 | 108 | 101 | 138 | 71 | 155 | 101 | 151 |
| 4 | 000005.jpg | 66 | 114 | 112 | 112 | 86 | 119 | 71 | 147 | 104 | 150 |
Table 6: Facial Attribute.
| Measure | |
|---|---|
| forehead height | 82 |
| middle face height | 68 |
| middle face height | 86 |
| left eye era | 216 |
| right eye era | 194 |
| eye to eye dist | 47 |
| eye to eyebrow dist | 17.5 |
| upper lip height | 6 |
| lower lip height | 11 |
| eyebrows distance | 29 |
| nose length | 46 |
| nose width | 41 |
| nose arc | 147 |
| eyebrow shape detector 1 | 141 |
| eyebrow shape detector 2 | 1 |
| eye slope detector 1 | -0.265 |
| eye slope detector 2 | 1.847 |
| eyebrow slope | -0.145 |
Table 7: Facial Feature Measurement.
| Shape | |
| Si | ze |
| Co | lor |
Table 8: Facial Feature Measurement.
$$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \mathrm {E} _ {\mathrm {i}} + \mathrm {E} _ {\mathrm {j}} + \mathrm {E} _ {\mathrm {k}} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} $$ $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$
Face Classification
DCNN techniques were used to detect and refuse offensive face pictures throughout the enrolling procedure. This will ensure the right students are enrolled and as a consequence, optimum performance.
By incorporating the ordered grid of vector-valued inputs into the kernel of an array of filters in a particular layer, the CNN generates feature maps. The triggering events of the organized feature maps are then computed using a non-linear corrected linear unit (ReLU). Local response normalization, or LRN, is used to normalize the new feature map that the ReLU produced. Spatial pooling (maximum or average pooling) is used to further calculate the result of the normalizing. Then, certain unneeded weights are initialized to zero using the dropout normalization approach, and this process often happens inside the fully linked layers before the categorization layer. In the fully connected layer, the classification of picture labels is done using the softmax activation feature.
| C | NN |
|---|
$$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ Fea.Extracted $$ \mathrm {E} = \mathrm {E} _ {1} + \mathrm {E} _ {2} + \dots + \mathrm {E} _ {n} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Classifier $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \mathrm {B} ^ {2} $$ Storage
Face Recognition
The face detection module receives some picture of some face after it has been captured by the camera. The locations in a photograph where humans are the most probably to be seen are found in this section. The extraction of features modules utilizes the face image as input after recognizing the face using a region proposal network (RPN) to determine the most crucial traits that will be used for categorization. A very brief vector of features that accurately depicts the facial picture is created by the module’s code. In this scenario, DCNN and a pattern classifier are used to contrast the recovered properties of the face picture to those stored in the face databases. The face image is then classified as either recognized or unfamiliar. If the picture face is recognized, the specific person’s test hall information is shown.
Prognosis
In this part of the course, the matching procedure is carried out using test live camera-captured classification files and training classified results. The difference is calculated using Eigen Vectors, and the results are utilized to represent the forecast accuracy.
Distance Metrics
Trained Data File
$$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Stastical $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Prediction Result visualization $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Test Data $$ \mathrm {E} = \frac {1}{2} \mathrm {A} ^ {2} + \frac {1}{2} \mathrm {B} ^ {2} + \frac {1}{2} \mathrm {C} ^ {2} $$ Stastical
Exam Hall Authenticator
By contrasting and evaluating the patterns, forms, and proportions of a student’s face characteristics and contours from the trained categorized file, this module may identify or validate them. An algorithm that mechanically encodes a facial image (a probing image), and then compares it to previously saved characteristics in the student’s database when it is input into the system.
Information
The person who submitted the photographs, as well as anyone who may be worried about the profile or a match, are then given this data. Quick results are provided to allow for prompt follow-up action.
Performance Evaluation Based on the context of this project, the following significant factors connected to the performance metrics will be addressed: A. True Positive (TP): The methods locate the True Positive (TP) the pupil’s name and determine that it is a Face. B. False Positive (FP): algorithms that identify the student and display the name even when there is no Face.
C. False Negative (FN): Although a face is there, the computer programs fail to recognize the student or their name. D. True Negative (TN): Nothing is being detected while there is no Face.
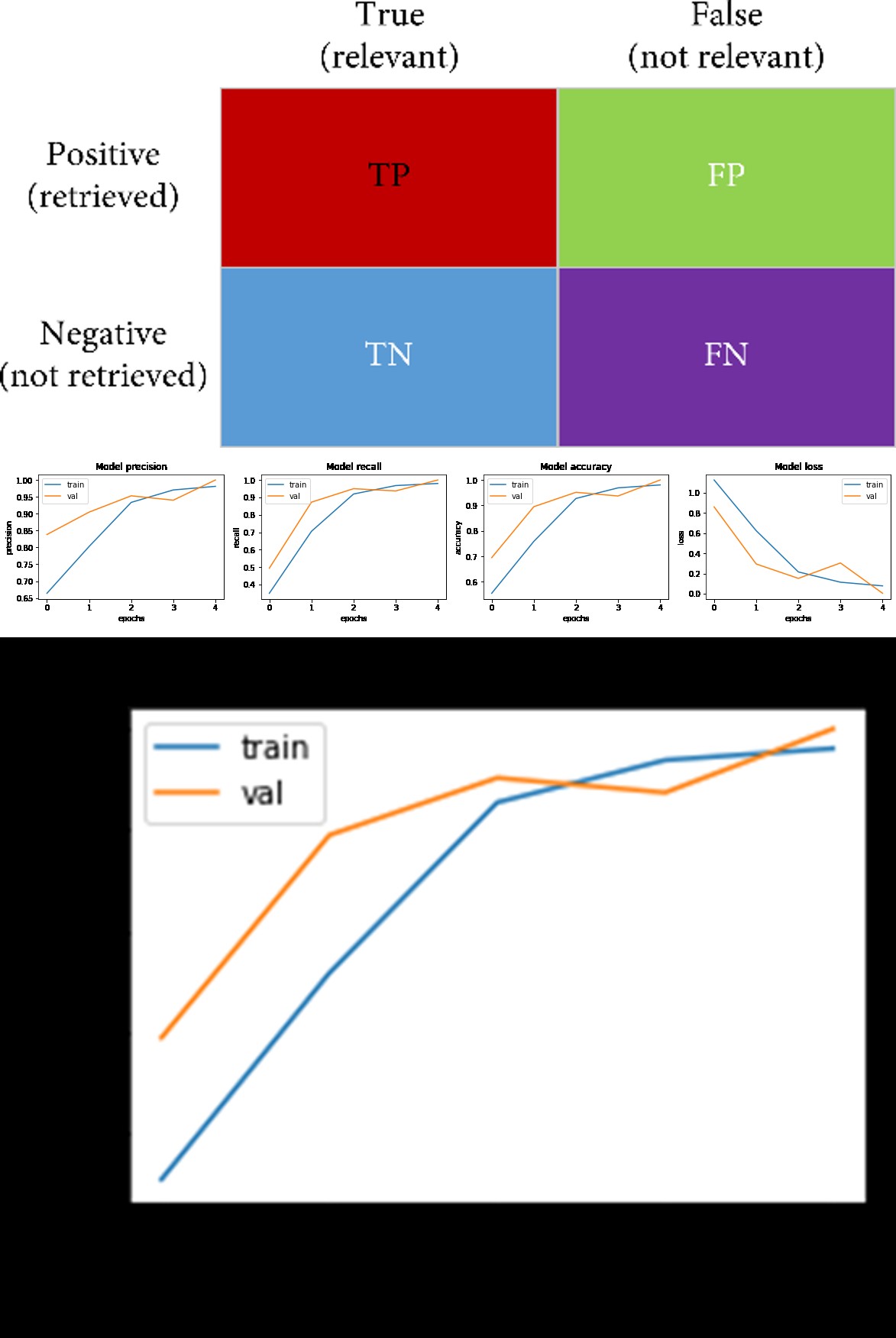
• Accuracy A model’s or algorithm’s correctness is a metric that indicates how well it operates and if it was trained appropriately. Accuracy in the context of this thesis refers to how effectively it works to recognize faces in ATMs. The following formula is used to determine accuracy. Precision is equal to (T P + T N)/ (T P + T N + F P + F N). Reliability: 0.9984025559105432
• Precision It represents the percentage of favourably projected situations that really turn out to be positive. Precision, as used in this thesis, refers to the percentage of objects expected to be Card Holders that are really Card Holder Faces that can be found in an ATM environment. The formula that follows is used to determine precision.
T P = TP / (TP + F P) Roughness: 0.9990234375
• Recall The ratio of actual positive instances to those that were expected to be positive is what matters. Remember this thesis refers to the percentage of projected Face that correctly identifies the cardholder. The formula that follows is used to determine recall. Remembering =T P/ (TP + F N) Inquiry: 0.9964285714285714
• F1 Score A balancing The F-measure or F-score is another name for it. An algorithm’s F1 rating, which includes recall and precision, is used to assess its accuracy. A high F1 score in the context of this thesis indicates that false positives and false negatives are less common. This demonstrates how well the model recognizes faces in an ATM context.
A mathematical model or method is said to be flawless if it’s F1 score is 1. This equation serves to compute it. F1_score: 0.9977122020583142 F1 = 2 (Precision Recall / Precision + Recall) A. Practice period The time it took to train the chosen machine learning algorithms on the dataset is measured in this thesis by the training time metric.
B. Prediction Speed In this thesis, prediction speed is employed as a metric to assess how quickly algorithms analyse and identify obstacles.
C. Lack of Function Using a loss operation, do feature matching between the output of the network’s segmentation and the real world, optimizing the weighting of the network on features retrieved at various resolutions rather than only concentrating on the pixel level.

D. Dcnn Overview Artificial intelligence (AI) technologies are developed using a machine learning technique known as deep learning. It depends on the idea of artificial neural networks (ANN), which analyse massive amounts of data by performing intricate analyses using multiple layers of cells. The variety of deep neural networks (DNN) is enormous. The most widely used kind of convolutional neural network with deep layers (CNN or DCNN) for video and image recognition of patterns. Conventional artificial neural networks gave rise to DCNNs, which employ a neural pattern in 3 dimensions modelled after an animal’s cortex of vision.
Although deep convolutional neural networks are frequently utilized to analyse natural language, their main applications are in the fields of recognizing objects, classification of images, and systems for recommendation. Deep Convolutional Neural Networks (DCNN) are a subset of Deep Learning (DL) techniques that differ from traditional Convolutional Neural Networks (CNN) in that they frequently have additional layers of concealment five, which are used to extract more data and improve prediction accuracy. DCNN comes in two distinct varieties. By raising the number of layers that are concealed or hidden layer nodes, one is generated. Contrary to other machine learning (ML) techniques that call for pre-selection of the input characteristics (or attributes), the DCNN method, which has been extensively and effectively applied to computer vision tasks like object localization, detection, and image classification, is a supervised learning exercise that uses the raw data to determine the classification features. The strength of DCNNs comes from their ability to be stacked. Employing a three-dimensional neural network, a DCNN concurrently analyses the red, green, and blue parts of the image. This drastically reduces the number of artificial cells required in comparison to feed-forward neural networks to evaluate a picture. Deep convolutional neural networks receive input from images and use that information to train a system for classification. The neural network replaces the multiplication of matrices with a novel mathematical procedure called “convolution”.
E. Algorithms
Empirical Finding
Unit Testing
The creation of scenarios for unit testing guarantees that the fundamental logic of the application is operating properly and that program inputs produce legal outputs. Verifying the inner program flows for each choice branching is crucial. It involves testing each individual piece of code that makes up the program. It is carried out following the end of each separate component before merging. This is an invasive architectural test that requires knowledge of its construction. Unit tests look at a given setup of a system, application, or company procedure and conduct basic tests at the component level. Unit tests are used to ensure that every separate company procedure route corresponds closely to the given standards and has established inputs and outcomes.
Validation Testing
The purpose of verification testing in software engineering is to ascertain if a current system conforms to the system requirements, carries out the specific tasks for which it was created, and satisfies the goals and needs of the company. This kind of testing is crucial, particularly if you want to be among the finest software testers. After the validation testing step, which comes second to verification testing, comes the software verification as well as the validation testing procedure.
Output Testing
- Reality test results against predicted outcomes.
- Log of Defects: Priority, Severity, Signs and symptoms, Description, Date Found.
- Test Report: A summary of the tests performed, GO/NO- GO advice, phase/iterations, and date. A testing methodology known as cause-and-effect analysis tests every combination of input values in a methodical manner. Testing in pairs - A number of factors affect how software behaves. Several variables are examined pairwise for their various values in bilateral testing.
User Acceptance Testing
User Acceptance Testing (UAT): User acceptance testing (UAT), sometimes referred to as testing an app, is the final stage of any software creation or change request cycle before becoming life. The last phase in any process of development is to ensure that the software operates as expected under real conditions. The system is put through a test by actual individuals to determine if it operates as planned under real-world conditions, to validate changes made, and to determine conformity with overall demands. The main objective of acceptance testing is to validate the consistency of the whole company procedure. User Acceptance Testing is carried out in an alternative testing environment. The creation of a change, an update, or a new feature is requested. There are tests for integration as well as unit tests. The world seems to be in order. However, when it becomes public, important problems begin to surface. Reworking and testing again are not the most expensive results when that happens.
Conclusion and Future Enhancement
Conclusion
It used to take a long time for pupils as well as instructors to manually record each student’s attendance in the test room. A facial identification system, which is often used to verify users via identification verification services, operates by recognizing and quantifying face features in a given image. A collection of features may be used to compare an individual’s face to an electronic image or a video clip. A technology for recognizing faces has been developed that is prepared to be used in the proposed system for the purpose of live examinee authentication with little to no human intervention to validate the candidate. This system is a study of the various attendance-taking tools currently available. Additionally, a completely computerized system may take its place. The administration of exam attendance may be improved with the use of this method. The administration will have to perform less work and will save time thanks to this approach. The recommended classification performance evaluation in terms of specificity, sensitivity, precision, accuracy, and score has been demonstrated using a confusion matrix. The recommended classification fared better than 10 current state-of-the-art classifiers in terms of recognition precision, according to the findings.
Future Enhancement
We plan on continuing to enhance the accuracy of the proposed classifier going forward so as to solve the possible spoofing problem brought on by phony subjects. Additionally, we may use this method to cast our votes across Bangladesh and India.
References
-
Kakadiaris IA, Dou P (2018) Multi-view 3D face reconstruction with deep recurrent neural networks. Image and Vision Computing 80(1): 80-91.
-
Shao X, Lyu J, Xing J, Zhang L, Li X, et al. (2019) 3D faces shape regression from 2D videos with multi- reconstruction and mesh retrieval. ICCVW, pp: 1-6.
-
Wu F, Bao L, Chen Y (2019) MVF-Net: Multi-view 3d face morphable model regression. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp: 959-968.
-
Zhou H, Chen P, Shen W (2018) A Multi-View Face Recognition System Based on Cascade Face Detector and Improved Dlib in Pattern Recognition and Computer Vision. MIPPR.
-
Renuka B, Sivaranjani B, Lakshmi AM, Muthukumaran DN (2018) Automatic enemy detecting defense robot by using face detection technique. Asian Journal of Applied Science and Technology 2(2): 495-501.
-
Sun X, Wu P, Hoi SCH (2018) Face detection using deep learning: An improved faster RCNN approach. Neurocomputing 299: 42-50.
-
Zhou E, Cao Z, Sun J (2018) Gridface: Face rectification via learning local homography transformations. Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, pp: 3-20.
-
Zhang ZK, Zhang Z Li, Qiao Y (2016) Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters 23(10): 1499- 1503.
-
Zhang T, Zheng W, Cui Z, Zong Y, Yan J, et al. (2016) A deep neural network-driven feature learning method for multi-view facial expression recognition. IEEE Transactions on Multimedia 18(12): 2528-2536.
-
Farfade SS, Saberian MJ, Li LJ (2015) Multi-view face detection using deep convolutional neural networks. International Conference on Multimedia Retrieval, pp: 643-650.
- Revolutionizing Property Measurement Through Artificial Intelligence: The Journey of PropertyMeasure.ai
- AI Infused Business Model Innovation for Competitive Advantage in the Era of Big Data and Digital Transformation
- Use of CPM/PERT in the Effort to Eradicate Polio
- Integrated Multimodal Deep Learning Framework for Early Detection of Mouth Cancer Using CT Imaging and Clinical Symptom Analysis
- Artificial Intelligence in Medical Robotics and Assistance: An Overview
- Server Migration with Multipath-QUIC